
适用于 Win10 x64 平台的离线OCR软件。支持截屏识别、粘贴图片,支持批量导入本地图片,将OCR结果输出到软件面板或本地文件。
- 免费:本项目所有代码开源,完全免费。
- 方便:解压即用,无需安装。不需要网络。
- 高效:OCR识别引擎是C++编译的 PaddleOCR-json (PP-OCRv2.6 cpu_avx_mkl)。只要电脑性能足够,通常能比在线OCR服务更快。
- 精准:默认使用PPOCR-v3模型库。除了能准确辨认常规文字,对手写、方向不正、杂乱背景等情景也有不错的识别率。可设置忽略区域排除水印,可设置文块后处理合并段落。

兼容性
- 系统支持 Win10 x64 及以上版本。
- CPU必须具有AVX指令集。常见的家用CPU一般都满足该条件。AVX支持的产品系列不支持存疑Intel酷睿Core,至强Xeon凌动Atom,安腾Itanium赛扬Celeron,奔腾PentiumAMD推土机架构及之后的产品,如锐龙Ryzen、速龙Athlon、FX 等K10架构及之前的产品
前言
关于忽略指定区域的特殊功能:
类似含水印的视频截图、含有UI/按钮的游戏截图等,往往只需要提取字幕区域的文本,而避免提取到水印和UI文本。本软件可设置忽略某些区域内的文字,来实现这一目的。当有大量的影视和游戏截图需要整理归档,或者想翻找包含某一段台词/字幕的截图;将这些图片提取出文字、然后Ctrl+F是一个很有效的方法。这是开发本软件的初衷。
关于离线OCR引擎 PaddleOCR-json :
对 PaddleOCR 2.6 cpu_avx_mkl C++ 的封装。效率高于Python版本PPOCR及部分Python编写的OCR引擎,通常比在线OCR服务更快(省去网络传输的时间)。支持更换Paddle官方模型(兼容v2和v3版本)或自己训练的模型,支持修改PPOCR各项参数。通过添加不同的语言模型,软件可识别多国语言。
简单上手
准备
下载压缩包并解压全部文件即可。
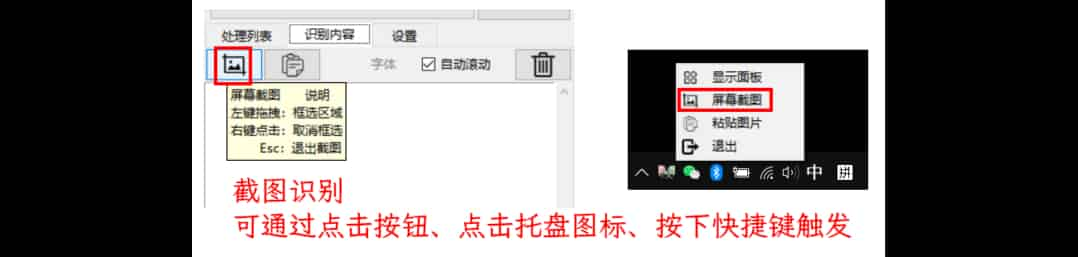
截图识别
点击截图按钮或自定义快捷键,唤起截图识别。
粘贴图片到软件
在任何地方(如文件管理器,网页,微信)复制图片,软件上点击粘贴按钮,自动识别。

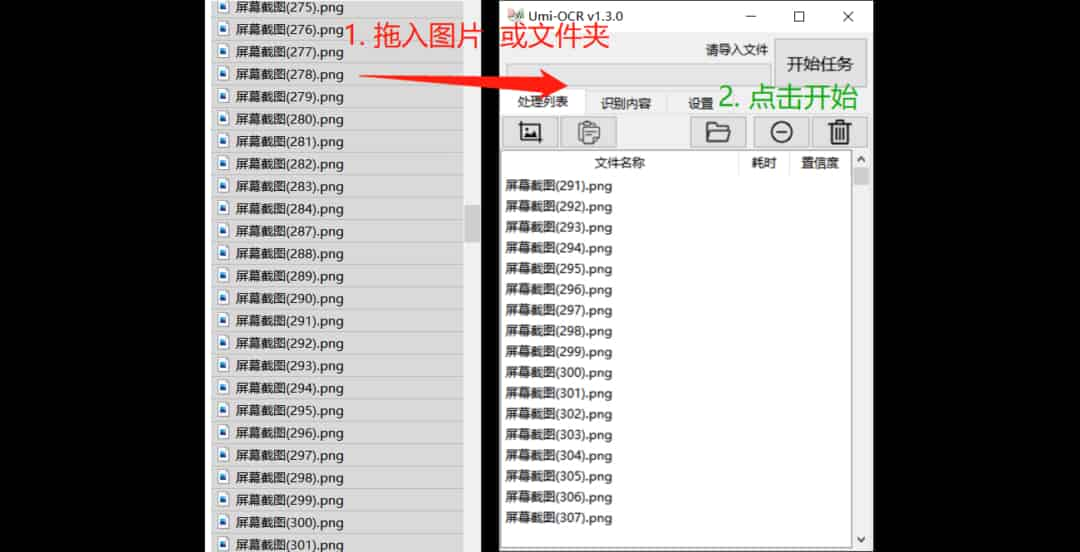
批量识别本地图片文件
将图片或文件夹拖进软件,批量转换文字。也可以点击按钮打开浏览窗口导入。
文本块后处理功能
OCR识别出的文本是按“块”划分的,通常一行文字分为一块,有时还会将一行误划分为多块,这给阅读带来了不便。文本块后处理就是对文本块进行再加工的过程,合并同一行或同一段落内的文字,按正确的顺序排序。
下图表示不同排版应该选用何种处理方案:

所有方案一览
横排-优化单行
将误划分为多块的同一行文字合并到一行。
横排-合并多行-左对齐
将多个左对齐的行视为同一段落,合并文字。
横排-合并多行-自然段
将多个左对齐的行视为同一段落,且第一行可以比后续行多空出开头两个字符。
横排-合并多行-模糊匹配
只要垂直投影有重迭,且行高一致的文本块,视为同一段落。
竖排-从左到右-单行 / 竖排-从右至左-单行
优化竖排识别,合并同一行文字,按从左到右或从右到左的顺序输出每一行。 注意,必须搭配支持竖排识别的模型库(识别语言)一起使用。
可视化预览
可以在忽略区域编辑器内预览文本块后处理的效果。编辑器中以虚线框标出识别到、经过后处理的文字块。
注意,这仅仅是借用了编辑器来展示后处理的效果,实际运行任务时 忽略区域机制 早于 后处理机制 执行,不受后处理的影响。
忽略区域功能
忽略区域是本软件特色功能,可用于排除图片中水印的干扰,让识别结果只留下所需的文本。
更新日志
v2.1.4 主要更新:
- 修复:引擎原始输出项的”text”为空时,导致文本分析越界的错误。
- 新增UI语言:葡萄牙语
PaddleOCR 插件相关:
- 修复:布尔类型选项不生效的问题。
- 修复:
繁体中文配置文件错误的问题。 - 优化:调整默认线程/内存限制,默认内存占用不超过系统总内存的一半。
- 优化:调整识别语言库结构,精简不必要的文件。
Linux 版本相关:
- 优化:
glibc依赖降级至2.31,兼容Debian-11等发行版。 - 修复:Docker 部署 在部分旧系统中报错
'code': 803的问题
评论(0)